This article focuses on the storage format of data in Cassandra, including data in memory and data on disk. Cassandra's write performance is very good, why write performance is so good? It has nothing to do with its data structure, and how much it has to do with its writing mechanism. At the same time, it will also analyze which factors will affect the performance of the read and what improvements Cassandra has made.
1. CommitLog: mainly records the data and operations submitted by the client. This data will be persisted to disk so that it can be used to recover data if it is not persisted to disk.
2, Memtable: the form of data written by the user in memory, its object structure is described in detail later. In fact, there is another form of BinaryMemtable. This format is currently not used by Cassandra and will not be introduced here.
3, SSTable: Data is persisted to disk, which is divided into Data, Index and Filter three data formats.
CommitLog data format
CommitLog has only one type of data, that is, the number of byte groups is formed according to a certain format, and it is written to the IO buffer and periodically flushed to disk for persistence. In the detailed configuration file of the previous article, CommitLog persistence has been mentioned. There are two ways, one is Periodic and the other is Batch. Their data formats are the same, except that the former is asynchronous, the latter is synchronous, and the frequency of data being scanned to disk is different. The related class structure diagram for CommitLog is as follows:
Figure 1. Related class structure diagram for CommitLog
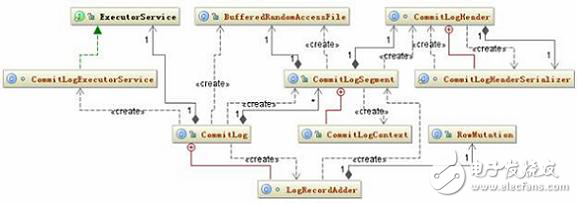
Its persistence strategy is also very simple, that is, the object RowMutaTIon where the data submitted by the user is first serialized into a byte array, and then the object and the byte array are passed to the LogRecordAdder object, and the write method of the CommitLogSegment is called by the LogRecordAdder object to complete the write operation. The code for this write method is as follows:
Listing 1. CommitLogSegment. write
Public CommitLogSegment.CommitLogContext write(RowMutaTIon rowMutaTIon,
Object serializedRow){
Long currentPosiTIon = -1L;
...
Checksum checkum = new CRC32();
If (serializedRow instanceof DataOutputBuffer){
DataOutputBuffer buffer = (DataOutputBuffer) serializedRow;
logWriter.writeLong(buffer.getLength());
logWriter.write(buffer.getData(), 0, buffer.getLength());
Checkum.update(buffer.getData(), 0, buffer.getLength());
}
Else{
Assert serializedRow instanceof byte[];
Byte[] bytes = (byte[]) serializedRow;
logWriter.writeLong(bytes.length);
logWriter.write(bytes);
Checkum.update(bytes, 0, bytes.length);
}
logWriter.writeLong(checkum.getValue());
...
}
The main function of this code is that if the current id based on columnFamily has not been serialized, a CommitLogHeader object will be generated based on this id, the position in the current CommitLog file will be recorded, and the header will be serialized, overwriting the previous Header. This header may contain multiple ids for the columnFamily corresponding to the RowMutation that is not serialized to disk. If it already exists, write the serialization result of the RowMutation object directly into the file buffer of the CommitLog and add a CRC32 checksum. The format of the Byte array is as follows:
Figure 2. CommitLog file array structure

The id of each different columnFamily in the above image is included in the header. The purpose of this is to make it easier to determine which data is not serialized.
The purpose of CommitLog is to recover data that has not been written to disk. How to recover from the data stored in the CommitLog file? This code is in the recover method:
Listing 2. CommitLog.recover
Public static void recover(File[] clogs) throws IOException{
...
Final CommitLogHeader clHeader = CommitLogHeader.readCommitLogHeader(reader);
Int lowPos = CommitLogHeader.getLowestPosition(clHeader);
If (lowPos == 0) break;
Reader.seek(lowPos);
While (!reader.isEOF()){
Try{
Bytes = new byte[(int) reader.readLong()];
reader.readFully(bytes);
claimedCRC32 = reader.readLong();
}
...
ByteArrayInputStream bufIn = new ByteArrayInputStream(bytes);
Checksum checksum = new CRC32();
Checksum.update(bytes, 0, bytes.length);
If (claimedCRC32 != checksum.getValue()){continue;}
Final RowMutation rm =
RowMutation.serializer().deserialize(new DataInputStream(bufIn));
}
...
}
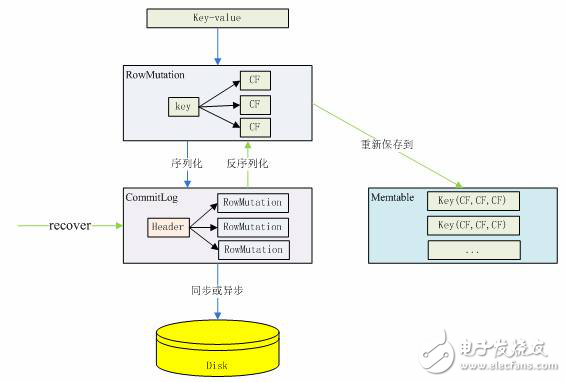
The idea behind this code is to deserialize the header of the CommitLog file as a CommitLogHeader object, look for the minimum RowMutation position in the header object that has not been written back, then fetch the serialized data of the RowMutation object based on this position, and then deserialize it into RowMutation. The object is then retrieved from the RowMutation object and saved back to Memtable instead of being written directly to disk. The operation of CommitLog can be clearly indicated by the following figure:
Figure 3. Change process of the CommitLog data format
Memtable in-memory data structure
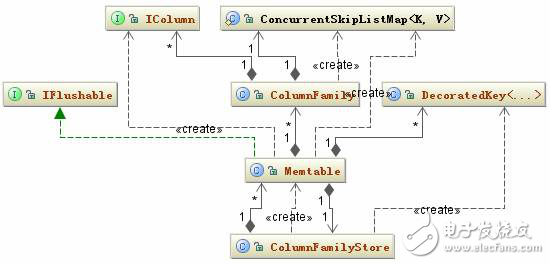
Memtable in-memory data structure is relatively simple, a ColumnFamily corresponds to a unique Memtable object, so Memtable is mainly to maintain a ConcurrentSkipListMap "decoratedkey, columnfamily="" style= "box-sizing: border-box;" type data structure, when When a new RowMutation object is added, Memtable just needs to see if the structure "decoratedkey, columnfamily="" style="box-sizing: border-box;" has already existed. If not, it will be added. If so, it will be taken out. The ColumnFamily corresponding to this Key, and then their Columns are merged. The structure diagram of the Memtable related class is as follows:
Figure 4. Memtable related class structure diagram
The data in the Memtable is flushed to the local disk according to the corresponding configuration parameters in the configuration file. These parameters have been detailed in the previous article.
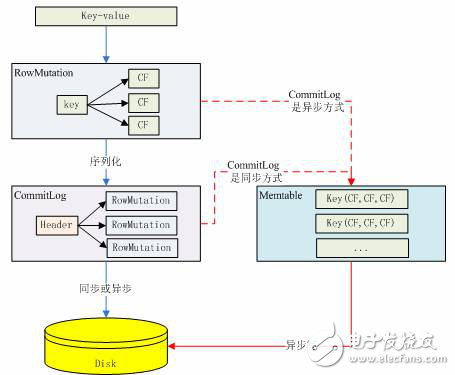
There have been many mentions in the past that Cassandra's write performance is very good. The good reason is because Cassandra writes that the data is first written to Memtable, and Memtable is the data structure in memory, so Cassandra's write is to write memory, the following figure Basically describes how a key/value data is written to the Memtable data structure in Cassandra.
Figure 5. Data is written to Memtable
SSTable data format
Each time a piece of data is added to the Memtable, the program checks to see if the Memtable has met the conditions written to disk. If the condition satisfies the Memtable, it will be written to disk. Let's take a look at the classes involved in this process. The related class diagram is shown in Figure 6:
Figure 6. SSTable persistence class structure diagram
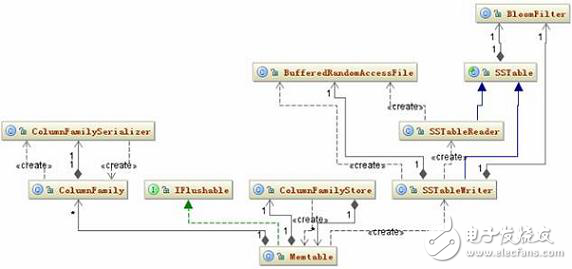
After the condition of Memtable is satisfied, it will create an SSTableWriter object, and then take out all the "decoratedkey, columnfamily="" style="box-sizing: border-box;" collection in Memtable, and write the serialized structure of the ColumnFamily object to In DataOutputBuffer. Next, the SSTableWriter is written to the Date, Index, and Filter files according to the DecoratedKey and DataOutputBuffer.
The Data file format is as follows:
Figure 7. Data file structure of SSTable

The Data file is organized according to the above byte array. When the data is written to the Data file, it will be written to the Index file. What data is written in the Index?
In fact, the Index file records the revelation address of all Keys and this Key in the Data file, as shown in Figure 8.
Figure 8. Index file structure

The Index file is actually an index file of the Key. Currently, only the Key is indexed. There is no index for the super column and the column, so matching the column is relatively slower than the Key.
After the Index file is written, the Filter file is written. The contents of the Filter file are the serialization result of the BloomFilter object. Its file structure is shown in Figure 9:
Figure 9. Filter file structure

The BloomFilter object actually corresponds to a Hash algorithm. This algorithm can quickly determine that a given Key is not in the current SSTable, and the BloomFilter object corresponding to each SSTable is in memory. The Filter file indicates a copy of the BloomFilter persistent. . The data format corresponding to the three files can be clearly indicated by the following figure:
Figure 10. SSTable data format conversion
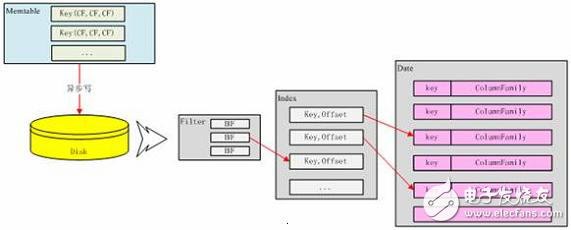
After the three files are written, one more thing to do is to update the CommitLog file mentioned above to tell the CommitLog that the current ColumnFamily stored in the header is not written to the minimum position of the disk.
In the process of writing Memtable to disk, the Memtable is placed in the memtablesPendingFlush container to ensure that the data stored in it can be read correctly when reading. This will be introduced later in the data read.
Data writingThere are two steps to writing data to Cassandra:
1. Find the node that should save this data
2. Write data to this node. The client must specify Keyspace, ColumnFamily, Key, Column Name, and Value when writing a piece of data. It can also specify Timestamp and the security level of the data.
The main related classes involved in data writing are shown in the following figure:
Figure 11. Insert related class diagram
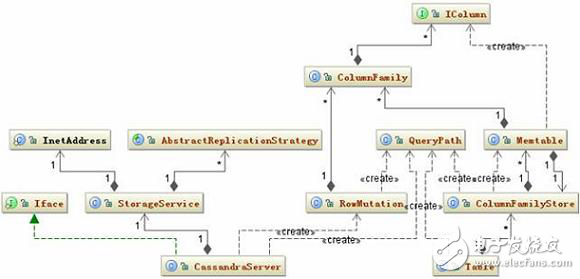
The big write logic is this:
When CassandraServer receives the data to be written, it first creates a RowMutation object and then creates a QueryPath object that holds the ColumnFamily, Column Name, or Super Column Name. Then save all the data submitted by the user in the Map "string, columnfamily=", style="box-sizing: border-box;" structure of the RowMutation object. The next step is to calculate which data should be saved by the node in the cluster based on the submitted Key. The rule for this calculation is to convert the Key into a Token and then find the closest node to the given Token based on the binary search algorithm in the Token ring of the entire cluster. If the user specifies data to save multiple backups, the nodes with the same number of backups will be returned in the Token ring in sequence. This is a basic list of nodes, after which Cassandra will determine if these nodes are working properly, if not looking for replacement nodes. Also check to see if a node is starting up. This kind of node is also within the scope of consideration and will eventually form a list of target nodes. Finally send the data to these nodes.
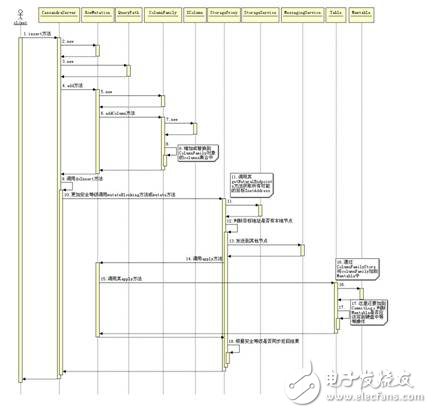
The next step is to save the data to Memtable and CommitLog. The return of the result can be asynchronous or synchronous depending on the security level specified by the user. If a node returns a failure, the data will be sent again. The following figure is a timing diagram for writing data to Memtable when Cassandra receives a piece of data.
Figure 12. Timing diagram of the Insert operation
This 12 port Usb charger has strong compatibility and can support iPad, iPhone, Samsung Huawei, tablet and other devices. At the same time, this type of 12 port mobile phone charger with built-in smart IC chip can automatically provide the best current for your device, which can provide up to 2.4A, increasing the charging speed by 30%.

12 Port Usb Charger,Ipad High Charger,12Port Mobile Phone Chargers,12Port Usb High Power Charger
shenzhen ns-idae technology co.,ltd , https://www.szbestchargers.com