Recently, the Facebook research team published an HPCA 2018 paper, including Caffe author Jia Yangqing and others, which deeply revealed the hardware and software infrastructure that supports machine learning within Facebook. Machine learning is widely used in almost all of Facebook's services, where computer vision is only a small fraction of resource requirements. In addition, Facebook relies on a variety of machine learning methods, including but not limited to neural networks. On the hardware side, CPU is used for reasoning, both CPU and GPU are used for training, and large-scale distributed training is performed.

Machine learning is at the heart of many of Facebook's key products and services. This article describes Facebook's hardware and software infrastructure that supports machine learning worldwide. Facebook's machine learning workload is very diverse: in practice, different services require many different types of models. This diversity has an impact on all layers in the system stack. In addition, most of the data stored on Facebook is transmitted through machine learning processes, which poses a serious challenge in delivering data to high-performance distributed training flows. The computational requirements are also large, requiring GPU and CPU platform training, and a large amount of CPU capacity for real-time reasoning. Addressing these and other emerging challenges requires a variety of efforts, including machine learning algorithms, software and hardware design.
Providing machine learning services to 2 billion users, how Facebook handles computing and data
As of December 2017, Facebook has more than 2 billion users. In the past few years, machine learning has been applied to this large-scale practical problem, forming a virtuous cycle of machine learning algorithm innovation, providing a large amount of training data for the model, and making progress with the help of high-performance computer architecture. On Facebook, machine learning offers key capabilities in almost all user experiences, including News Feed, voice and text translation, photos and live video categorization.
Facebook uses a variety of machine learning algorithms in these services, including support vector machines, gradient-enhanced decision trees, and many types of neural networks. This article describes several important aspects of the data center infrastructure that supports machine learning on Facebook. The infrastructure includes an internal "ML-as-a-Service" flow, an open source machine learning framework and distributed training algorithms. From a hardware perspective, Facebook uses a large number of CPU and GPU platforms to train the model to support the necessary training frequency for the required service delay time. For machine learning reasoning, Facebook relies primarily on the CPU to handle the main functions of all neural network ranking services, such as the News Feed, which account for most of the computing load.
Facebook brings together a large portion of all stored data through a machine learning process, and this ratio increases over time, improving the quality of the model. The vast amount of data required for machine learning services challenges the global scale of Facebook data centers. Several techniques are used to efficiently provide data to models, including decoupling of data feeds and training, data/computation co-location, and network optimization. At the same time, the size of Facebook also offers unique opportunities. During off-peak hours, the daily load cycle provides a large number of available CPUs for distributed training algorithms. Facebook's computing fleet is spread across 10 data centers, and the scale also provides disaster recovery capabilities. Disaster recovery planning is important because timely delivery of new machine learning models is critical to Facebook's operations.
Looking ahead, Facebook expects machine learning to grow rapidly with existing features and new services. For teams that deploy the infrastructure for these services, this growth means more challenges. While optimizing the infrastructure on existing platforms is beneficial, we are still actively evaluating and creating new hardware solutions while maintaining algorithm innovation.
Key insights about Facebook's machine learning:
Machine learning is widely used in almost all of Facebook's services, and computer vision is only a small part of the resource requirements.
Facebook relies on a variety of machine learning methods, including but not limited to neural networks.
A large amount of data is transmitted through the machine learning process, which causes engineering and efficiency losses outside of the compute nodes.
Facebook currently relies heavily on CPU for reasoning, both CPU and GPU for training, but from a performance-to-power ratio perspective, it continues to prototype and evaluate new hardware solutions.
Facebook's global user size and corresponding day activity patterns result in a large number of machines that can be used for machine learning tasks, such as large-scale distributed training.
Machine learning on Facebook
Machine learning (ML) is an example of a product that uses a series of inputs to build a tuning model and uses it to create representations, predictions, or other forms of useful signals.
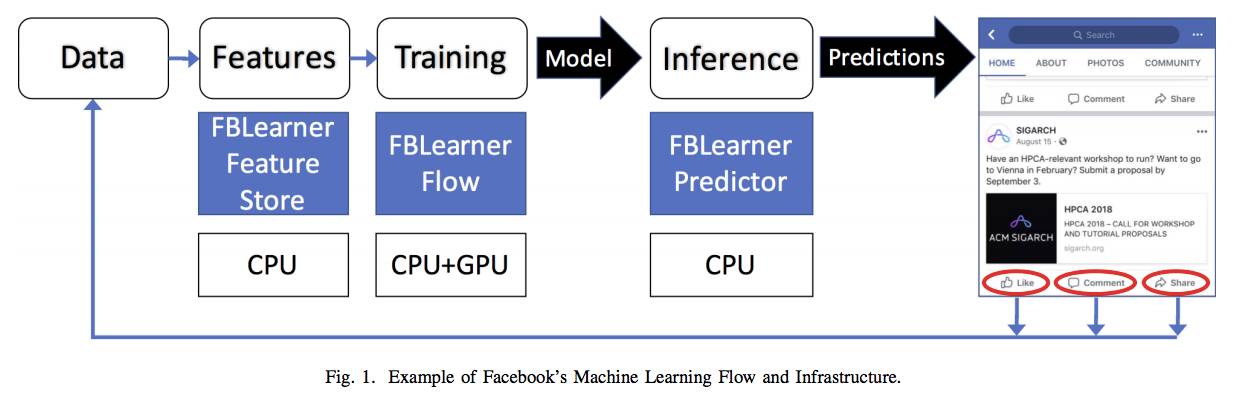
Figure 1 shows this process, consisting of the following steps, which are executed in sequence:
1) Establish the training phase of the model. This phase is usually performed offline.
2) Run the inference phase of the training model in production and perform a (one) set of real-time predictions. This phase is performed online.
A notable feature of machine learning on Facebook is the impact of the vast amounts of data that might be used to train the model. The size of this data will generate a lot of heroes, covering the entire infrastructure.
Main services that utilize machine learning:
Most of Facebook's products and services use machine learning, including:
News Feed: The ranking algorithm lets users see the stories most relevant to them each time they visit Facebook.
Ads (Ads): Use ML to target ads to users.
Search: Provides specialized sub-searches in various vertical areas, such as videos, photos, people, events, and more.
Sigma: A common classification and anomaly detection framework for a variety of internal applications, including site integrity, spam detection, payment, registration, unauthorized employee access, and event recommendations.
Lumos: Extracts advanced attributes and embedding from images and their content, enabling algorithms to automatically understand images.
Facer: Facebook's face detection and recognition framework.
Language Translation: Content Internationalization Service for Facebook.
Speech recognition: A service that converts an audio stream into text.
In addition to the main products mentioned above, there are more long tail services that take advantage of various forms of machine learning. The number of long tails for products and services is hundreds.
Machine learning model
All machine learning-based services use "features" (or inputs) to produce quantized output. Machine learning algorithms used on Facebook include Logistic Regression (LR), Support Vector Machine (SVM), Gradient Elevation Decision Tree (GBDT), and Deep Neural Network (DNN). LR and SVM are effective methods for training and using predictions. GBDT can increase the accuracy with additional computing resources. DNN is the most expressive and may provide the highest accuracy, but it also utilizes the most resources (at least an order of magnitude more than the amount of computation required by linear models such as LR and SVM). All three types correspond to models with more and more free parameters that must be trained by optimizing the accuracy of the labeled input samples.
In deep neural networks, there are three commonly used classes: Multilayer Perceptron (MLP), Convolutional Neural Network (CNN), and Recurrent Neural Network (RNN/LSTM). MLP networks are typically used for structured input features (usually ranking), CNN is used as a spatial processor (usually for image processing), and RNN / LSTM networks are sequence processors (usually used for language processing). Table 1 illustrates these ML model types and corresponding products/services.
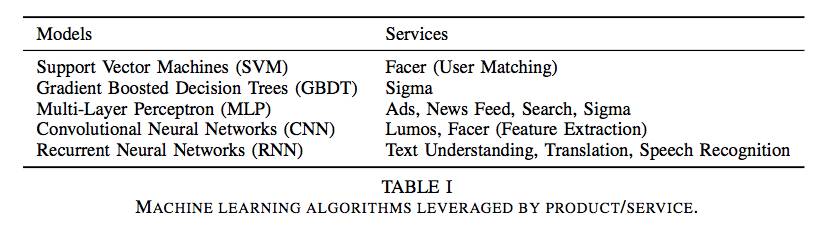
Table 1: Products/Services Using Machine Learning Algorithms
ML-as-a-Service in Facebook
Facebook has some internal platforms and toolkits designed to simplify the task of using machine learning in products. Mainly including FBLearner, Caffe2 and PyTorch. FBLearner is a suit for three tools, each focusing on different parts of the machine learning process. FB Learner uses the internal job scheduler to allocate resources and schedule jobs on shared GPUs and CPU pools, as shown in Figure 1. Most of the ML training on Facebook runs through the FBLearner platform. These tools work together with the platform to improve the efficiency of ML engineers and help them focus on algorithm innovation.
FBLearner Feature Store: The Feature Store is essentially a catalog of several feature generators that can be used for training and real-time prediction. It can be used as a marketplace that multiple teams can use to share and discover features.
FBLearner Flow: Facebook's machine learning platform for model training.
FBLearner Predictor: Facebook's internal reasoning engine that uses models trained in Flow to provide forecasts in real time.
Deep learning framework
For deep learning, Facebook uses two distinct but synergistic frameworks: PyTorch for research optimization and Caffe2 for production optimization.
Caffe2: Facebook's in-house production framework for training and deploying large-scale machine learning models. Caffe2 focuses on several key features required for the product: performance, cross-platform support, and coverage of basic machine learning algorithms such as Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), and Multilayer Perceptrons (MLP) Etc., these algorithms have sparse or dense connections, up to tens of billions of parameters. Caffe2's design involves a modular approach that shares a unified graphical representation across all backend implementations (CPU, GPU, and accelerator). A separate execution engine serves different graphics execution needs, and Caffe2 introduces third-party libraries (for example, cuDNN, MKL, and Metal) on different platforms to achieve optimal runtime on different platforms.
PyTorch: Facebook's preferred framework for AI research. It has a front end that focuses on flexibility, debug and dynamic neural networks for quick experimentation.
ONNX: The full name Open Neural Network Exchange (Open Neural Network Exchange) is a format that represents a deep learning model in a standard way to achieve interoperability across different frameworks.
Hardware resources for machine learning on Facebook
(Detailed analysis see the original paper)
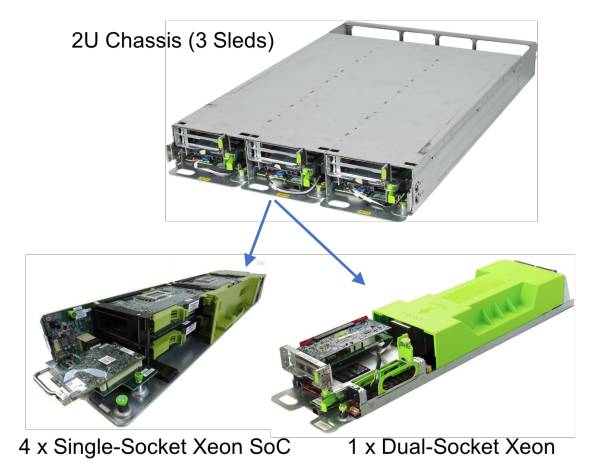
Figure 2: CPU-based computing server

Figure 3: Big Basin GPU server design, including 8 GPUs in a 3U chassis.
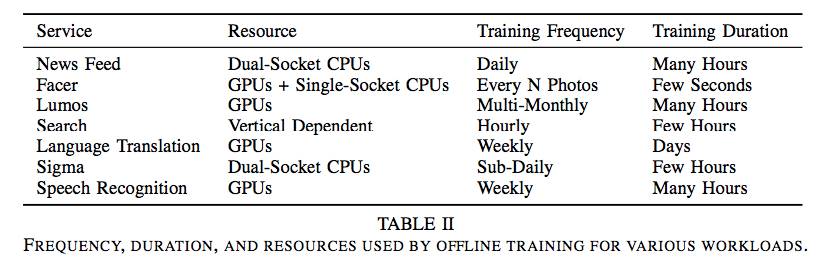
Table 2: Frequency, duration, and resources used for offline training for various workloads.
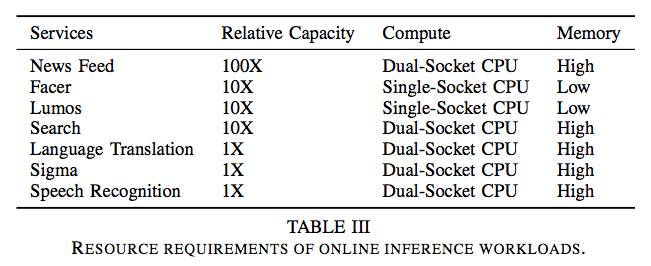
Table 3: Resource requirements for online inference workloads.
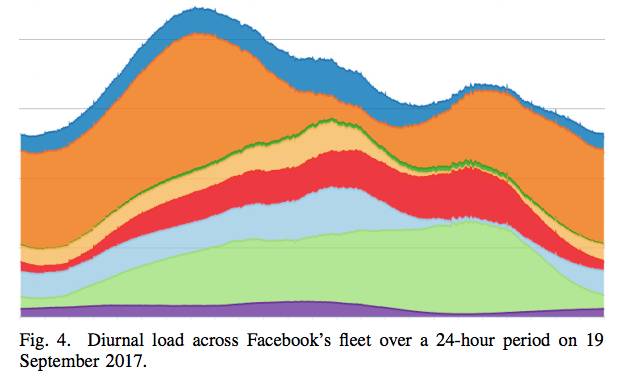
Figure 4: The daily load of all the Facebook's fleets during the 24 hours on September 19, 2017.
in conclusion
Machine learning-based workloads are becoming more and more important, and their impact covers all parts of the system stack. In this regard, the computer architecture community has shown increasing interest in how best to address emerging challenges. While previous work has been around the necessary calculations to effectively handle ML training and reasoning, the situation will change given the additional challenges that arise when the solution is applied on a large scale.
At Facebook, we identified several key factors that play a decisive role in the design of our data center infrastructure: the importance of data and computer co-location, the importance of handling various ML workloads, not just Computer vision, and opportunities due to idle capacity in the daily calculation cycle. When designing end-to-end solutions for open source hardware, we considered each of these factors and the open source software ecosystem that balances performance and availability. These solutions provide a powerful impetus for today's large-scale machine learning workloads serving more than 2.1 billion people, as well as an interdisciplinary effort by experts in machine learning algorithms and system design.
Copper Lugs,Copper Cable Lugs,Plating Copper Cable Lugs,Copper Tube Terminal Lugs
Taixing Longyi Terminals Co.,Ltd. , https://www.lycopperlugs.com