The picture shows a complex case of creating a training data set for an intersection that lacks road markings in fPro. (Source: rFpro)
The verification challenge for SAE Level 4 and 5 self-driving cars has been a major concern for driving simulation specialist rFpro, and Chris Hoyle, Director of Technology at fFpro, said that the emergence of Automated Cars for the Internet has brought a series of new unknowns to the automotive industry. . In the future, automakers will establish a database containing thousands of simulation test scenarios to meet the challenges of automotive verification.
According to Hoyle, the key questions that must be answered at the moment include: How can we be sure that the Net-autonomous vehicles can operate safely under any conditions? How can we guarantee the comprehensiveness and rigor of the test, but at the same time meet the test cycle and cost requirements? Do we have ways to speed up the development of autonomous vehicles before entering the verification phase, but at the same time avoid danger to public road users?
Hoyle said he often encountered relevant discussions. He believes that compared with real-world tests in the real world, analog simulation tests have the advantages of large coverage and short test cycles, but the premise is that they must be applied correctly.

rFpro is testing at a crossroads in Paris and you can see that the road markings at this crossroads are vague. (Source: rFpro)
New simulation platform
rFpro claims to have launched the world's first commercial platform for simulation, training and development of autonomous vehicles. It can test self-driving cars in a variety of imaginable environments. According to the report, one of the key features of the platform is "accurately replicating real-world test environments with high precision." Through a three-year project, rFpro has used high-precision scanning technology (more information, please click here) to convert a large number of real roads into simulated test scenarios, and finally created a "simulation test library." The user can select various simulation test scenarios in the library and control various variable inputs such as "weather" to "pedestrian". Currently, this technology has been adopted by two large OEMs, three self-driving car developers and one driverless racing product line. However, rFpro did not disclose further details for reasons of commercial confidentiality.
With a set of computers that work around the clock, manufacturers can accumulate millions of miles of simulated test miles each month. Hoyle explained: “From a statistical point of view, the average human driver has traveled 100 million miles per year and a traffic accident has occurred. However, it is difficult for us to actually accumulate this level of testing in self-driving car simulation tests. In fact, the "data" of human drivers is so outstanding because in the daily driving, most of our mileage is "nothing happens." Because of this, we can eliminate this part of "no accidents." “mileage, and through analog technology to let the network of self-driving cars encounter a “million-year-first†incident every few seconds, and then significantly shorten the simulation test cycle. In the future, car manufacturers will build contains thousands of simulation tests The database of the scene, and the self-driving car must successfully pass these test scenarios before it can be verified."
Each time a test fails, several standard tests for this scenario will be added to the simulation test scenario library. In addition, vehicles must not only pass every test successfully, but must also ensure stable performance.
Hoyle said that this test library, which uses regressive logic to run repeatedly, can ensure that any new improvements to self-driving cars will not affect existing functions. "In order to achieve this goal, rFpro can not only run multiple experiments in parallel on a group of devices, but also can extend an experiment on multiple CPUs and GPUs to cope with the diverse data sources (including multiple The complexity introduced by cameras, lidars, radar sensors, etc.)

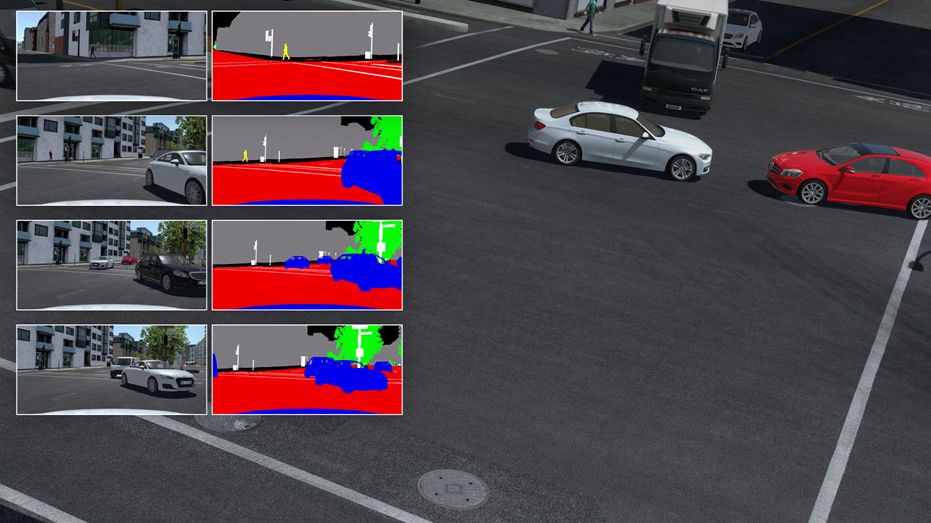
Each frame of training data used for monitoring learning includes semantic segments, instance segments, optical flow algorithms, depth, and marker target data. The figure shows an example of semantic segmentation. (Source: rFpro)
Standardized simulation
Such intensive testing takes some time to achieve the desired result. However, Hoyle expects that in the next five years, the rate of increase of new test scenarios will be reduced to statistically lower levels than human driver error rates. At this point, the real physical verification process in the real world can be started.
Hoyle believes that if the progress is satisfactory, the automotive industry will develop a global library of standardized test scenarios. Once verified by the standard library, any auto-driving model can enter the next stage of testing - that is, sampling a part of the scene from Curry. , conduct real tests in the real world.
But this brings another question: How can we guarantee the comprehensiveness and rigor of this scene library? According to Hoyle, the irony is that humans are very good at testing auto-driving cars. "Because humans have random and unpredictable characteristics, they never repeat; humans make mistakes, and their performance changes with emotional and fatigue levels." "Currently, the number of human drivers that can be supported in a single simulation test has increased to 50. We can test the performance of self-driving cars in urban centers with dense population or road users, and do not need to bear the risk of casualties.
rFpro expects that by the end of this year, the number of human pilots who have joined the test alone will increase to 250, and they will be responsible for the testing of one or more self-driving cars on the Internet.
The efficient development of artificial intelligence (AI) systems is inseparable from the ability to learn, summarize, and improve from failure before starting retests. Hoyle emphasized that we will also feedback frequently encountered borderline cases (one of which exceeds the system limit) or extreme cases (where two or more parameters exceed the system limit) to the system, thus continuously enriching the system's knowledge base. .
We can build a training database to demonstrate the correct behavior that should have been demonstrated in a failed test, and each database should contain data from all sensor models, including virtual cameras, lidars, and radars. Hoyle stated that each frame of training data should be associated with "ground truth" data, including semantic segments, instance segments, optical flow algorithms, depth, and marker target data. "In this logic, our model can be monitored Study and adapt to each new failure model."
Hoyle, however, added that, despite this, we still have a vital element that must always be remembered. “Humans are the best source of unbiased input because even on the same road under the same weather conditions, humans drive They also do not drive in exactly the same way. In addition, they can find some anomalies, anger or accidents and may react inappropriately to other road users' actions!"
Energy 8000,Energy Vape Pen,Energy 8000 Disposable,Energy 8000 Puff Disposable Vape
Shenzhen Zpal Technology Co.,Ltd , https://www.zpal-vape.com