Image segmentation is based on human eye recognition, and human eye recognition is a segmentation method from the whole to the part. For the first time, this paper proposes a new indicator that simulates human eye discrimination. The result is far better than the existing method and proves that it is more consistent with the human eye discrimination result.
Image segmentation is often based on human eye recognition, and human eye recognition is a segmentation method from the whole to the part. Starting from the overall and local directions, this paper proposes a novel and efficient enhanced calibration measurement method (E-measure) for the evaluation of binary foreground images. It is very reliable by simply combining local and global information. Evaluation results.
For GT (GroundTruth, truth map) and FM (ForegroundMap, foreground map) predicted by the segmentation algorithm, the meaning of the image evaluation index is to calculate the similarity between FM and GT, which is a value between 0-1 (see As probability), 1 means exactly the same, and 0 means different results according to different algorithms, which are considered completely different (or the opposite of GT). GT is often hand-marked by researchers,
It is generally believed that GT represents the result of human eye segmentation. The goal of the evaluation index algorithm is to obtain the same result as the image classification performed by the human eye. At present, the widely used IOU is an error measurement (pixel level) based on local information, while ignoring the global information of the image, resulting in inaccurate evaluation.
E-measure is an evaluation method based on the difference between local pixel information and global mean information. We use 5 meta-measures on 5 benchmark data sets to prove that E-measure is far superior to the existing measurement methods, and in our proposal The best results have been obtained on the human eye sorting dataset, which proves that it has a high degree of consistency with the subjective evaluation of people.
The problem leads to: in the tube, you can only see the leopard
Whether the evaluation index is reasonable or not plays a decisive role in the development of a model in a field. The most widely used evaluation index in the existing foreground map detection is IOU (Intersection-Over-Union), as shown in Figure 1, The formula of IOU can be expressed as formula 1.
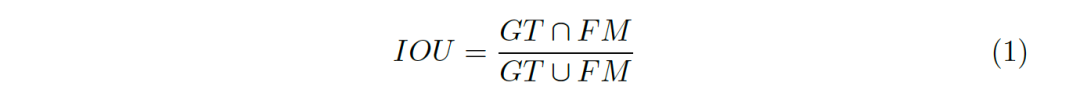
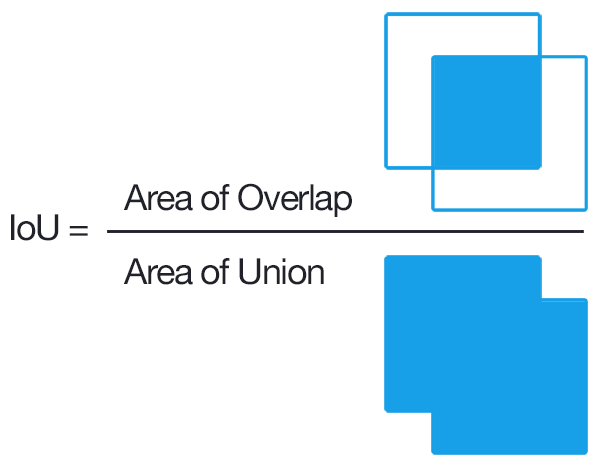
Figure 1: Visual representation of IOU
It is not difficult to see that IOU is an evaluation method based on local pixel differences and lacks global information. As shown in Figure 2, what is shown in (d) is nothing but a noise map. It is obvious that the image in (c) is more similar to the GT in (b), and (d) may actually only correspond to a completely white or black foreground. The results of the graphs are similar, and for all white or all black images, we can think of them as dissimilar (but not the similarity value is 0, in fact, 0 generally means the opposite). The result of passing the IOU algorithm tells us that (d) is better than (c)! This is obviously unreasonable.
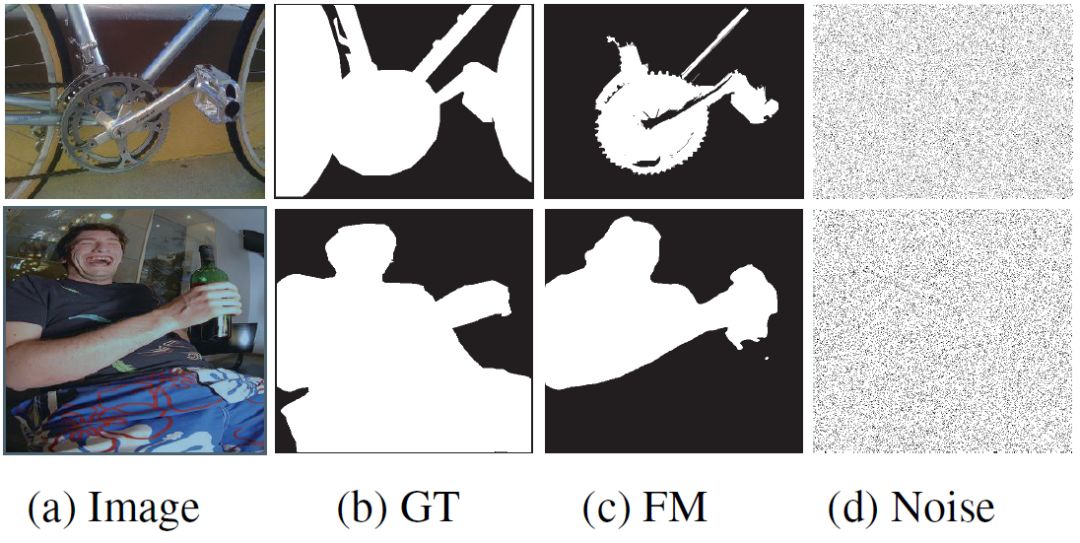
Figure 2: Comparison of FM evaluations of different types of prospects
Only based on local pixel differences may be effective for computers, but it does not conform to the human eye's mechanism for segmenting images. Let's analyze a simple example experimentally, as shown in Figure 3. The blue range is GT and the red range is FM. It can be seen that the FM shapes of (a) and (b) are very different, but their intersection with GT is exactly the same, resulting in exactly the same results.
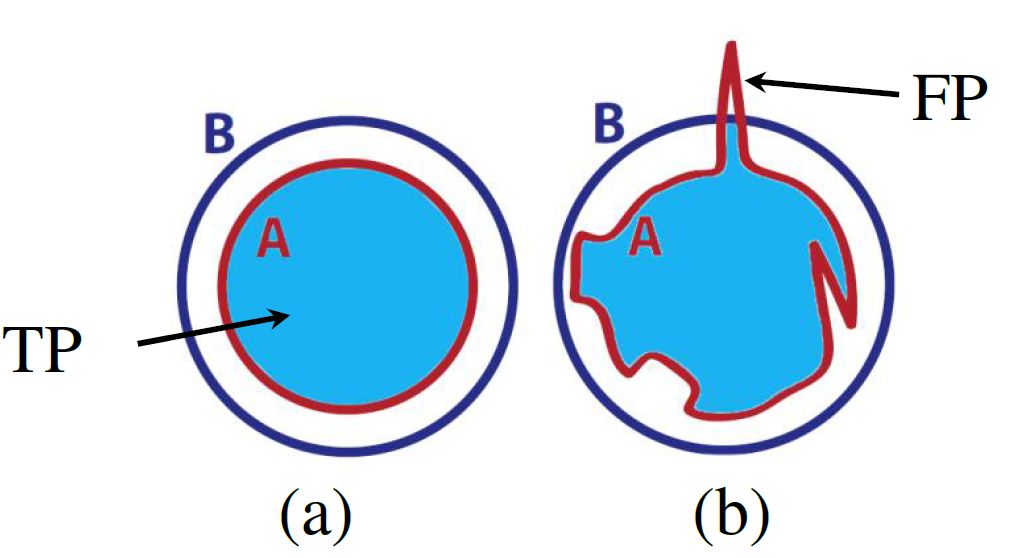
Figure 3: IOU simple analysis, the blue range is GT, red is FM, and the intersection area in (a) and (b) is the same
Because the IOU is only evaluated based on local pixel differences, it can only get a local optimal result, and it is difficult to get a comprehensive evaluation result. We need a comprehensive evaluation index that is in line with human vision.
Solution: Seeing six ways, hearing all directions
Since the current evaluation indicators all consider the error of a single pixel, they lack the consideration of global information, which leads to inaccurate evaluation. For this reason, we consider combining local information with global information for measurement.
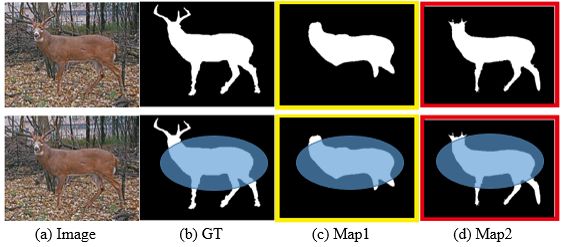
Figure 4: (b) is the segmentation result of the original image (a), Map1(c) and Map2(d) are the segmentation results of the two algorithms respectively
Let's first look at an example. From the results of the two segmentation algorithms in Figure 4, Map1 and Map2, we judge that the similarity between the result and the GT will take into account the global similarity, such as the entire deer body part. Through this judgment, the difference in the similarity between the two is small. And then make a partial detailed judgment (see Figure 5)). We find that the segmentation result of Map2 contains more details (feet) compared with Map1. Therefore, as shown in Figure 6, we will think that the segmentation result of Map2 is better than Map1.
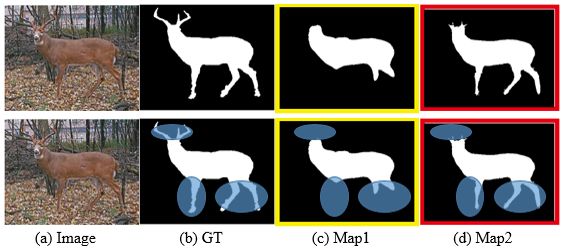
Figure 5: (b) is the segmentation result of the original image (a), Map1(c) and Map2(d) are the segmentation results of the two algorithms respectively
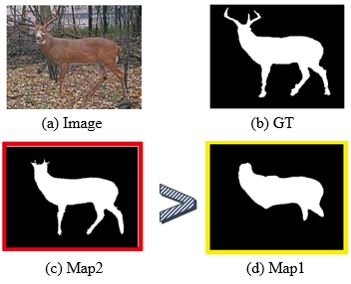
Figure 6: (b) is the segmentation result of the original image (a), Map1(c) and Map2(d) are the segmentation results of the two algorithms respectively
1. Combine global information and local information
We consider the image-level statistical information to be considered, and choose the global pixel mean μ as the image-level statistical information, because the global mean can represent the global information of the image and is simple to calculate. As shown in Figure 7(c)(d), 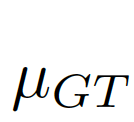
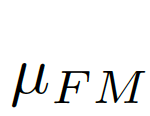
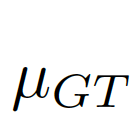 ,
,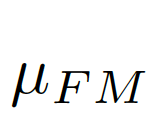 The difference is used as a deviation matrix combining global information
The difference is used as a deviation matrix combining global information
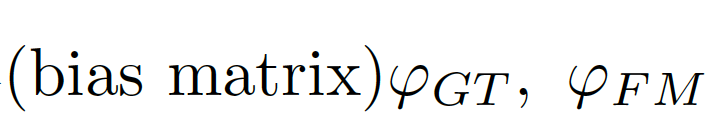
.
2. Error estimation
Calculate the bias matrix (biasmatrix) 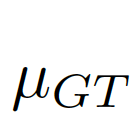
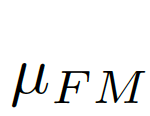
The deviation matrix is ​​a continuous value between [0-1]. We use the alignment matrix ξ to evaluate the error between the deviation matrices:
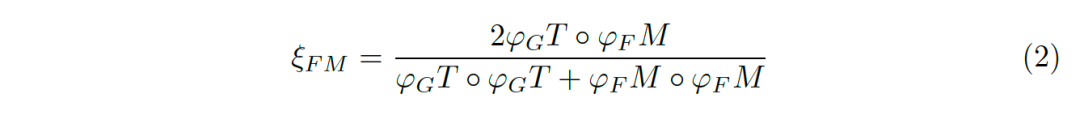
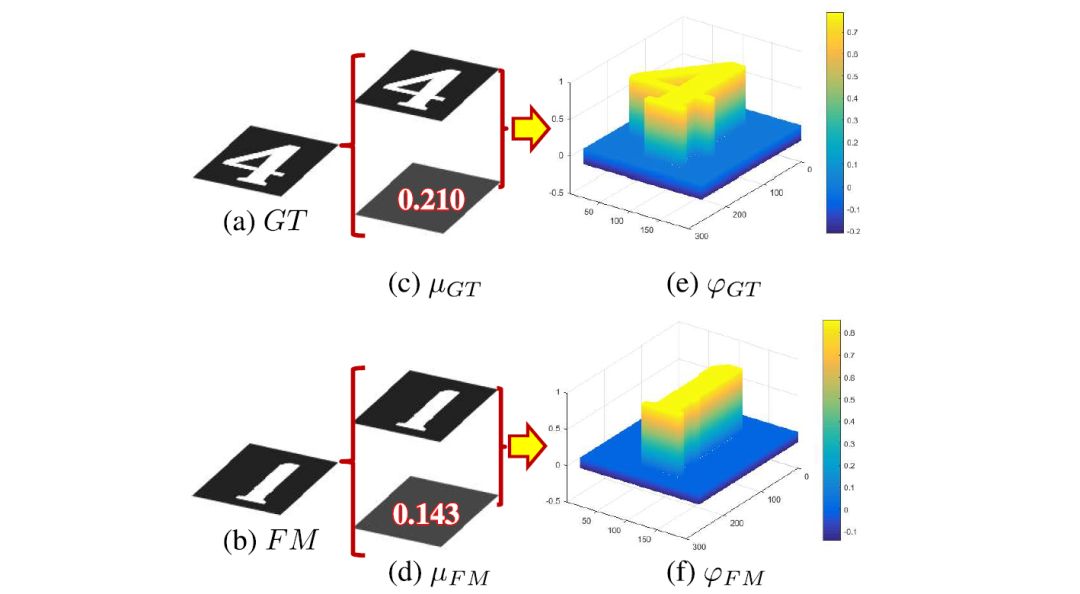
Picture 7: Combining global and local information. 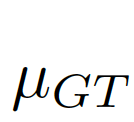
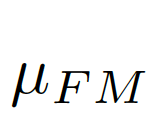
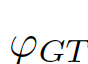 ,
,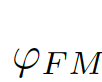 A bias matrix that combines global information and local information (biasmatrix)
A bias matrix that combines global information and local information (biasmatrix)
among them For the Hadamard, the numerator
For the Hadamard, the numerator
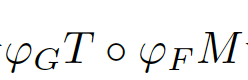
Price error, and
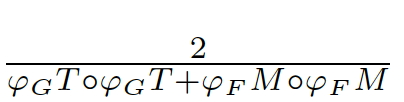
Scale the evaluation result to [-1,1], where -1 means completely opposite, and 1 means identical. That is, for each local value error that contains global information, we can calculate an error estimate between [-1,1].
3. Non-linear transformation
We need an evaluation index between [0,1], so we need to scale the value range of [-1,1] to between [0,1]. For the binary classification result output by a random classifier, that is, the randomly generated FM, the error with GT should be uniform, that is, the error should be evenly distributed between [-1.1], so that we can directly use the linear transformation Scale its value range to [0,1] (for example, using
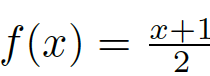
).
But in fact, all classifiers should be much better than random classifiers. That is to say, the output FM of many methods is similar to GT and rarely opposite, that is, most of the evaluation scores are concentrated in [0,1] Only a very small part appears in [-1,0]. In this case, it is no longer appropriate to continue to use linear functions to scale the range, because this will cause most of the results to be concentrated to more than 0.5. Lack of discrimination. Secondly, the result of human eye evaluation is to evaluate the similarity between FM and GT, not dissimilarity (or negative similarity), which also shows that it is not appropriate to use linear scaling. And simply setting all the values ​​between [-1,0] to 0 (such as the very famous relu activation function in neural networks) will lose some evaluation results, so it is not desirable.
Based on the above analysis, we propose a nonlinear transformation function:
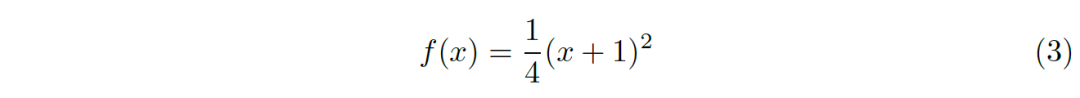
This function is actually just for the above function
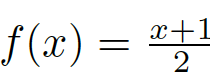
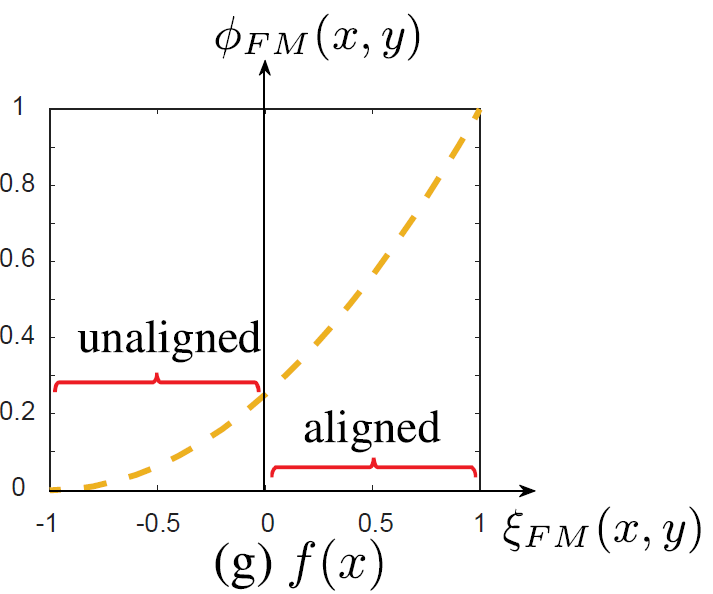
Figure 8: Non-linear transformation function, which scales the values ​​between [-1,0] to a smaller range, and scales the values ​​between [0,1] to a larger range
4. Comprehensive estimation
We scale all the errors to between [0,1], and get the error result within the range (4):
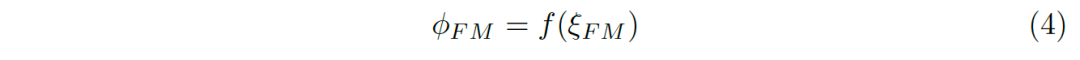
E-measure is defined as the synthesis of all position error results:
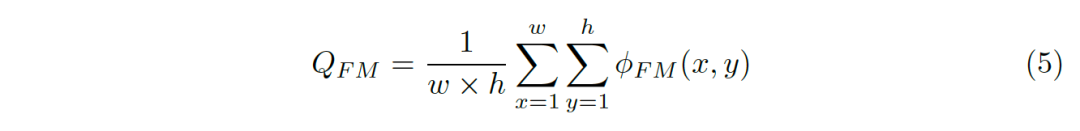
Metametric experiment proves validity
In order to prove the validity and reliability of the indicators, researchers use meta-metric methods to conduct experiments. By proposing a series of reasonable assumptions, and then verifying the degree to which the index meets these assumptions, the performance of the index can be obtained. In short, a meta-metric is a kind of evaluation index. The experiment uses 5 meta-metrics:
Meta metric 1: Application ranking
An important reason to promote the development of the model is application requirements. Therefore, the ranking result of an indicator should be highly consistent with the ranking result of the application. That is, a series of foreground images are input into the application program, and the application program obtains the sorting result of its standard foreground image. The evaluation result obtained by an excellent evaluation index should be highly consistent with the sorting result of the standard foreground image of the application program. As shown in Figure 9 below.
Picture 9
Meta-metric 2: State-of-the-art vs. General Results
The evaluation principle of an indicator should be inclined to select those detection results obtained by the most advanced algorithm rather than those general results that do not consider the content of the image (such as the central Gaussian map). As shown in Figure 10 below.

Picture 10
Meta-metric 3: State-of-the-art vs. random results
The evaluation principle of an indicator should be inclined to select those detection results obtained by the most advanced algorithm rather than those random results that do not consider the content of the image (such as Gaussian noise map). as shown in picture 2.
Meta metric 4: manual sorting
As an advanced primate, humans are good at capturing the structure of objects. Therefore, the ranking results of the evaluation indicators for foreground map detection should be highly consistent with human subjective rankings. We form the artificially sorted data set FMDatabase by randomly selecting the foreground image group from all the data sets in proportion to the human eye sorting. As shown in Figure 11 below.

Picture 11
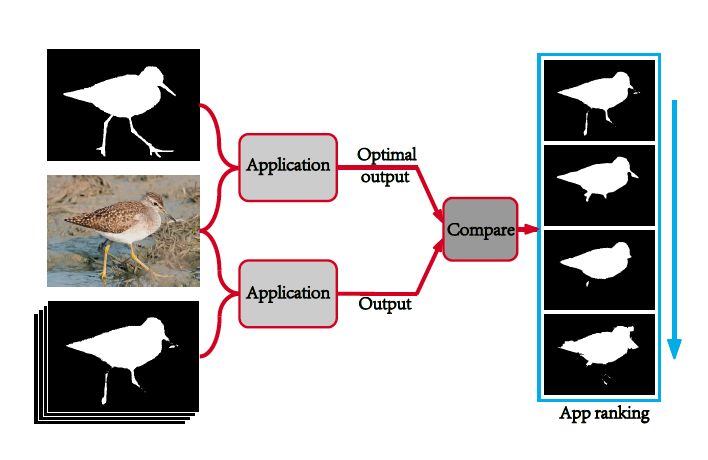
Meta-metric 5: Reference GT random replacement
The original indicator is considered to be a model with a good test result. When the reference Ground-truth is replaced with the wrong Ground-truth, the score should be lowered. As shown in Figure 12.
Picture 12
Experimental results
This paper conducts extensive tests on five challenging data sets with different characteristics to verify the stability and robustness of the indicators.

Figure 13
The experimental results show that our indicators are more robust and stable on the PASCAL, ECSSD, SOD and HKU-IS datasets. At the same time, our indicators also have the best results on FMDatabase (MM4).
Fiber Optic Test Equipment And Fiber Tools
Fiber Optic Test Equipment And Fiber Tools
Fiber Optic Test Equipment And Fiber Tools
Sijee Optical Communication Technology Co.,Ltd , https://www.sijee-optical.com