PricewaterhouseCoopers has recently launched a series of machine learning information diagrams that showcase the history of machine learning, key methods and how the future will affect social life. The basic concept part includes the combing of the intricate relationship between the various universities of machine learning; the application part describes the role of machine learning in society. As a professional consulting organization, PwC's infographics are very professional and are worthy of collection. Xinzhiyuan said on this basis. [Enter the new wisdom yuan background, reply "170422" to download the complete information icon]

How can AI become the mainstream of business? This requires a combination of different research methods and a lot of human wisdom.
We are in an era of breakthrough breakthroughs in AI: more complex neural networks with effective speech recognition training data bring Amazon's Echo and Google's Home to millions of households. The increased accuracy achieved by deep learning in image, speech and other pattern recognition has made Microsoft and Google's machine translations more widely used. Enhancements to image recognition enable Facebook's photo search and AI-related features in Google Photos. Overall, these advances have made the ability of machine identification to be largely used by consumers.
How to make similar progress in business? This requires high-quality training data, digital data processing, and data scientists. It also requires a lot of human intelligence, such as asking language experts to adjust and refine the computable and logical business context to make the computer realize business. Logical reasoning in the field. Business leaders also take the time to teach machines to integrate their intelligence into processes in specific areas.
Some statistics-oriented machine learning research genres, such as the Connected School, the Bayesian School, and the Analogy School, worry that the “human-in-the-loop†approach promoted by the semiotic school cannot be extended. However, we expect this ring of several genres, human and machine feedback, to become more common within the enterprise over the next few years.
The evolution of machine learning: the integration of various schools, and finally make automatic machines possible
Artificial intelligence researchers of various factions have long been competing with each other for a long time. Is the time for mutual cooperation coming? They have to shake hands and talk, because only the cooperation of the algorithm integration can achieve true universal artificial intelligence (AGI). Below, let's take a look at what kind of process the machine learning method has gone through, and what will happen in the future?

Symbolists: People who use the rule-based symbology to make inferences. Most AIs revolve around this approach. The methods of using Lisp and Prolog belong to this group, and the methods using SemanTIcWeb, RDF and OWL also belong to this group. One of the most ambitious attempts was Cyc, developed by Doug Lenat in the 1980s, to try to code our understanding of the world with logical rules. The main drawback of this approach is its vulnerability, because in the marginal case, a rigid knowledge base always seems to be inapplicable. But in reality, such ambiguity and uncertainty are inevitable. Love method: rules and decision trees
Bayesians: A group that uses probabilistic rules and their dependencies for reasoning. The Probabilistic Graph Model (PGM) is a general method of this school. The main computer system is the Monte Carlo method for sampling distribution. This method is similar to the semiotic method in that the interpretation of the result can be obtained in some way. Another advantage of this approach is that there is a measure of the uncertainty that can be expressed in the results. Love method: Naive Bayes or Markov
ConnecTIonists: Researchers in this group believe that intelligence originates from a simple mechanism of high interconnectivity. The first specific form of this method is the perceptron that appeared in 1959. Since then, this method has disappeared and resurrected several times. Its latest form is deep learning. Love method: neural network
EvoluTIonists: A process of applying evolution, such as crossover and mutation, to achieve an initial intelligent behavior. In deep learning, GA does have to be used instead of the gradient descent method, so it is not an isolated method. This school also studies cellular automata, such as Conway's "Life Game" and Complex Adaptive System (GAS). Love method: genetic algorithm
The analogizers: pay more attention to psychology and mathematics optimization, and extrapolate to make similarity judgments. The analogy school follows the principle of “nearest neighborsâ€. Product recommendations on various e-commerce sites (such as Amazon or Netflix's movie ratings) are the most common examples of analogy. Love method: support vector machine (SVM)
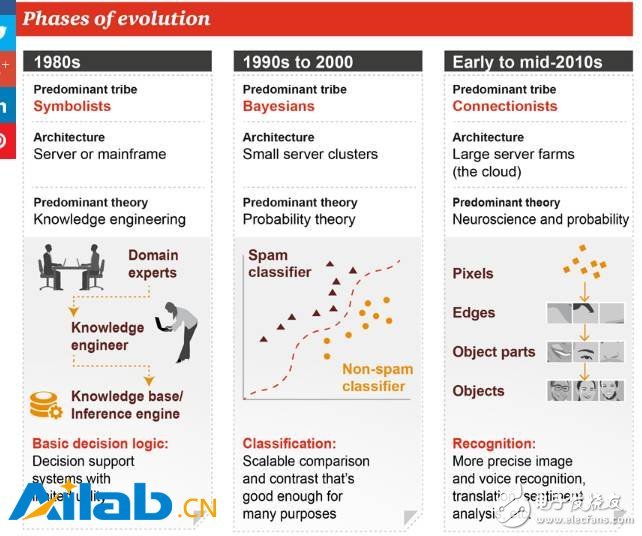
In the 1980s, the popular symbolism school, the leading method was Knowledge Engineering, which was created by experts in a certain field to make certain decision-making aids in specific fields, so-called “expert machinesâ€.
Beginning in the 1990s, the Bayesian school developed, and probability theory became the mainstream idea at that time. The principle based on it was an expandable comparison and comparison. This method can be applied to many scenarios.
By the end of the last century, the connected school has been booming, and the methods of neuroscience and probability theory have been widely used. Neural networks can more accurately identify images, speech, and perform tasks such as machine translation and even senTIment analysis. At the same time, because the neural network requires a lot of computing, the infrastructure is also a large-scale data center or cloud from the servers of the 1980s. I believe that everyone is very familiar with this part of the content.
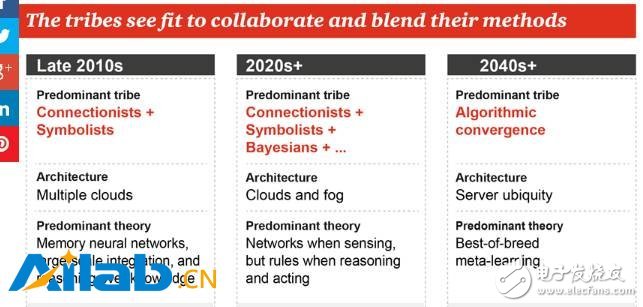
Nowadays, the various schools have begun to learn from each other. In the first decade of the 21st century, the most remarkable is the combination of the connected school and the symbolic school, which resulted in a memory neural network and an intelligent body capable of simple reasoning based on knowledge. The infrastructure is also transforming to large-scale cloud computing.
In the second decade, the Connected School, the Symbol School, and the Bayesian School will also be merged together. In fact, we have now seen such trends, such as the Bayesian RNN of DeepMind, and the main situation will be the perception task. The neural network is done, but it involves the inference and action or the need to manually write the rules.
From 2040 onwards, according to PwC's prediction, the mainstream school will become the algorithmic convergence, that is, the various algorithms will be merged together, when the machine learns autonomously, that is, meta-learning, the computing service will have nowhere. No.
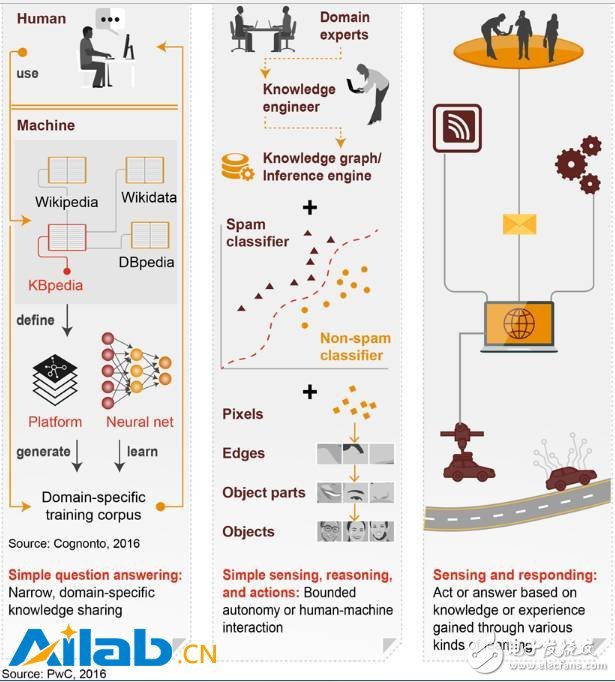
Machine learning: working principle and applicable scenarios
Machine learning makes humans and machines more connected by enabling humans to "teach" how machines are learned. The machine learns by processing the appropriate training set that contains the various features needed to optimize an algorithm. This algorithm enables machines to perform specific tasks, such as classifying emails.
However, the benefits go far beyond filtering emails, which were done ten years ago. Nowadays, with the help of machine learning, drones can take close-up shots of places such as bridges in real time, and then quickly and accurately assess the scope of reconstruction projects.
Below, PwC's infographics outline the workings of machine learning, the relationship between machine learning and artificial intelligence, and where companies should use them.

Machine learning can generate and identify specific objects, such as faces, by "learning" large amounts of data without the need for human programming. Machine learning is currently the most commonly used algorithm in commercial applications.
So, what is the specific relationship between machine learning and artificial intelligence?
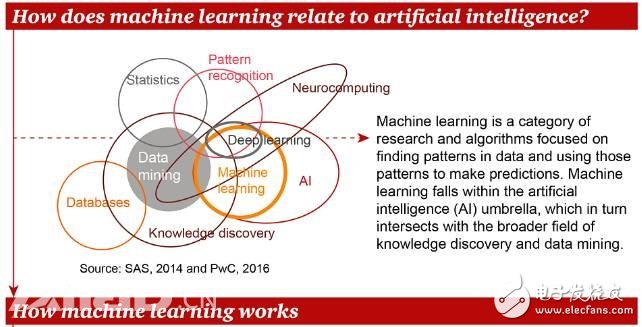
Machine learning is a type of research and algorithm that focuses on finding patterns from data and predicting them based on these patterns. Machine learning belongs to artificial intelligence, and its relationship with data mining, statistics, pattern recognition and other related fields is shown in the figure above. Let's take a look at how machine learning works.
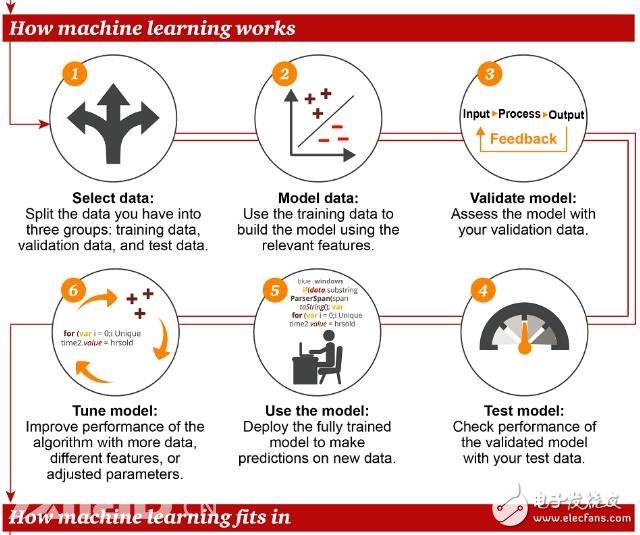
According to the summary of the PwC information map, the main processes/steps of machine learning:
Select data: This process is divided into three parts, namely training data, verification data, and test data.
Data Modeling: Using training data to build models involving related features
Validation model: validate the model with validation data
Debugging model: In order to improve the performance of the model, using more data, different features, and adjusting parameters, this is also the most time-consuming and labor-intensive step.
Use models: deploy model-trained models to predict new data
Test model: validate the model with test data and evaluate the performance of the model
Next, let's look at what kind of position machine learning is in the traditional methods of traditional programming and statistics.
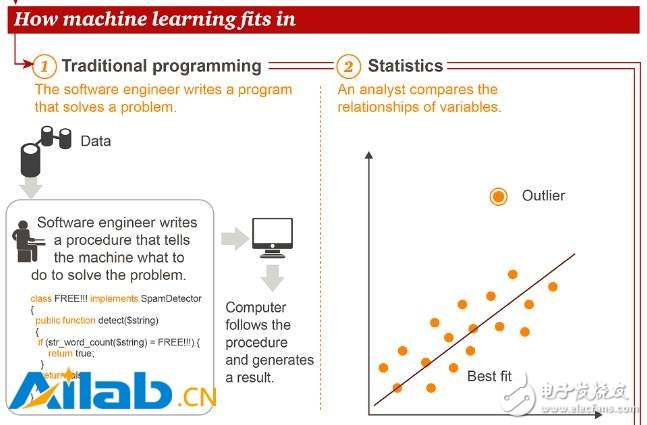
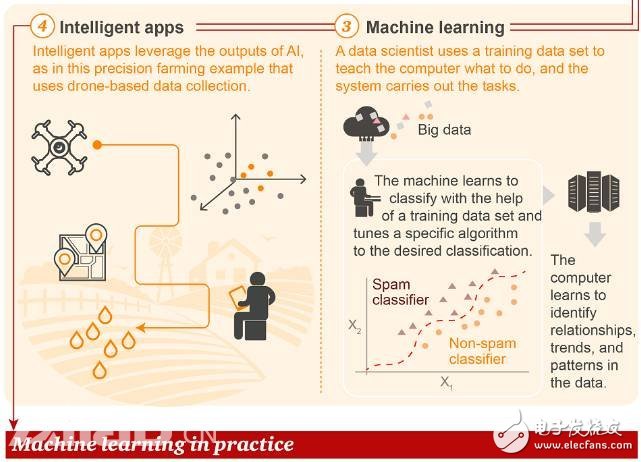
Unlike traditional programming and statistical methods, in machine learning, data scientists use training data to "educate" a computer and then let the computer perform tasks. As a result, an intelligent application (Intelligent App) is produced. The example cited in the figure is intelligent agriculture, which performs precise fertilization and irrigation operations through data collected by drones.
There are many applicable scenarios for machine learning in practical applications. The following figure shows three examples:

1. Fast 3D Mapping and Modeling For a railway bridge reconstruction project, PwC data scientists and domain experts apply machine learning to data collected by drones. This combination makes it possible to perform precise monitoring and fast feedback on ongoing work.
2. Strengthen analysis to mitigate risk In order to detect insider trading, PwC combines machine learning with other analytical techniques to discover more comprehensive user profiles and gain deeper insight into complex suspicious behavior.
3. Predicting the best performer PwC uses machine learning and other analytical techniques to assess the potential of each horse in the Melbourne Cup.
Practical application machine learning: What is the correct algorithm for a specific task?
Artificial intelligence and machine learning are hot topics in the corporate world, and company leaders have high expectations for how to use them to improve and automate business processes. In fact, according to PricewaterhouseCoopers' 2017 Global Digital IQ Survey, about 54% of organizations around the world are investing heavily in AI, a figure that will increase to 63% in three years.
So how does AI solve business problems, such as helping you figure out why customers are lost or assessing the risks of credit applicants? It depends on many factors, especially the data used by the algorithm and the type of training. What is the correct algorithm for a particular task? The report investigates the most commonly used algorithms and the business problems they solve.
The most commonly used algorithms and their use cases are listed below.

There are many algorithms commonly used in machine learning, and which ones need to be used depends largely on the data you are on and their characteristics, your training goals, and especially the specific usage scenarios. Unless you have a special case, you don't have to use the most complicated algorithm. The following are common machine learning algorithms.
1. Decision Trees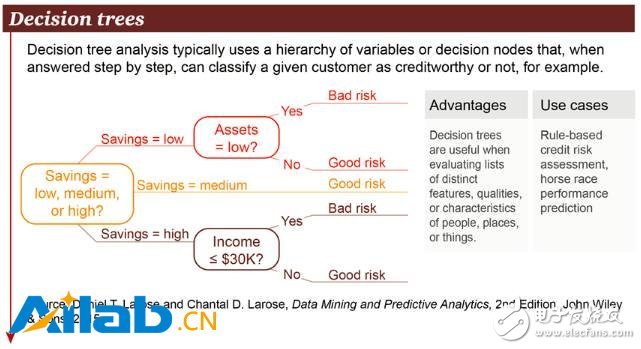
A decision tree is a decision support tool that uses a tree or decision model and sequence possibilities. Includes the consequences of various incidents, resource costs, and efficacy. From the perspective of business decision-making, in most cases, the decision tree is the minimum value that a person needs to ask for a yes/no question in order to assess the probability of making a correct decision. It allows you to deal with this problem in a structured and systematic way, and then come to a logical conclusion.
2. Support vector machine
Support Vector Machine (SVM) is a binary classification algorithm. Given a set of two types of N-dimensional local points, the SVM produces an (N - 1)-dimensional hyperplane to divide these points into two groups. Suppose you have two types of points, and they are linearly separable. The SVM will find a line dividing the points into 2 types, and this line will be as far away as possible from all points. On a scale, the biggest problems currently addressed using SVM (with appropriate modifications) include display advertising, human splice site identification, image-based gender detection, and large-scale image classification.
3. Logistic regression
Regression is a very common method. Among them, logistic regression is a powerful statistical method that can model a binomial result and one (or more) explanatory variables. It estimates the relationship between a categorical dependent variable and one (or more) independent variables by estimating the probability of using a logical operation, which is the cumulative logical distribution.
In general, logistic regression can be used in the following scenarios:
Traffic analysis
Credit score
Measuring the success rate of marketing campaigns
Predict the revenue of a product
Will there be an earthquake on a certain day?
4. Naive Bayes classification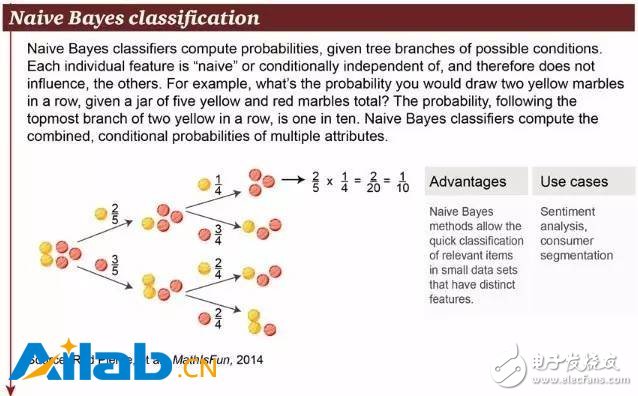
Naive Bayes classification is a very simple classification algorithm. The equation P(A|B) is the posterior probability, P(B|A) is the probability, P(A) is the class prior probability, and P(B) ) is the prediction of prior probability. The basic basis of Naive Bayes is this: for the given item to be classified, the probability of occurrence of each category under the condition of this occurrence, which is the largest, is considered to belong to which category. Its practical use examples are:
Classify a new article into technology, politics, or sports
Check if a piece of text expresses positive or negative emotions
For face recognition software
Customer classification
5. Hidden Markov Model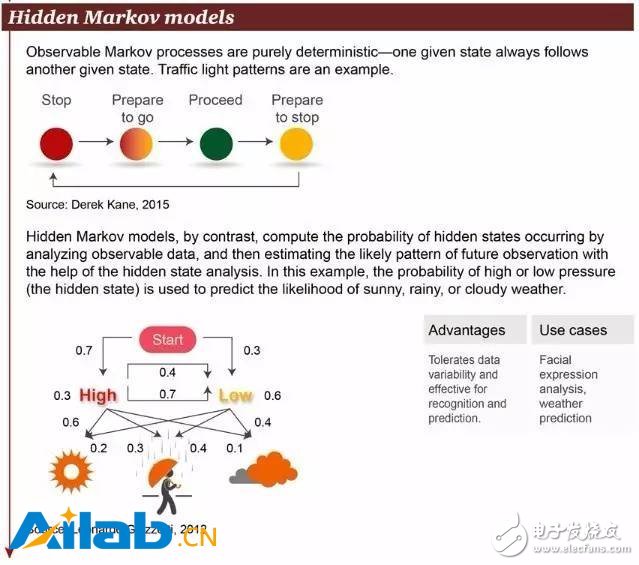
The observable Markov decision process is deterministic—a given state always follows another given state. For example, the mode of traffic lights.
In contrast, the hidden Markov model calculates the probability of a hidden state by analyzing observable data, and then estimates the patterns that may be observed in the future by analyzing the hidden state. An example is the possibility of predicting whether the weather is sunny, rainy or cloudy by analyzing the probability of high air pressure (or low air pressure).
6. Random Forest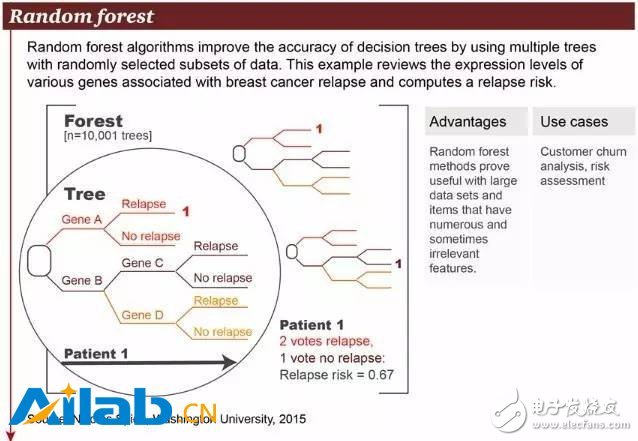
The random forest algorithm combines multiple trees and uses a randomly selected subset of data to improve the analysis accuracy of the decision tree. The example in the figure above shows the different genes and their probabilities associated with breast cancer recurrence. The advantage of the random deep forest algorithm is its ability to handle large-scale data sets, as well as a large number of seemingly unrelated data that can be used for risk assessment and customer information analysis.
7. Recurrent neural network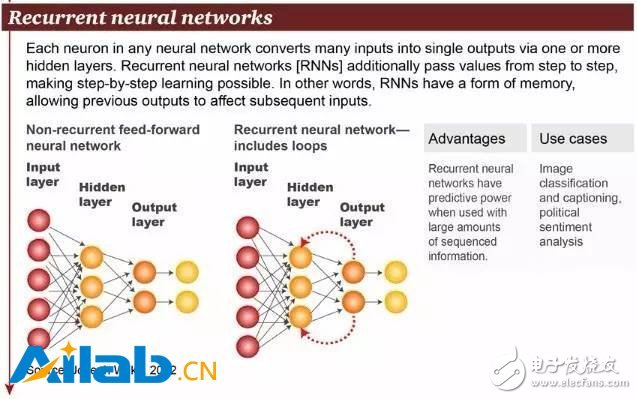
In fact, recurrent neural networks (RNN) are a general term for two artificial neural networks. One is the Recurrent Neural Network, and the other is the Recursive Neural Network. The interneuronal connections of the time recurrent neural network constitute a directed graph, while the structural recurrent neural network recursively constructs a more complex deep network using a similar neural network structure. RNN generally refers to a time recurrent neural network, as shown in the figure above.
Time-recurrent neural networks can describe dynamic time behavior because, unlike the feedforward neural network accepting input from a particular structure, the RNN cyclically passes states in its own network, thus accepting a wider range of time series structure inputs. Handwriting recognition is the first successful use of RNN research. Other applications include image classification, graph generation and sentiment analysis.
8. Long-term and short-term memory (LSTM)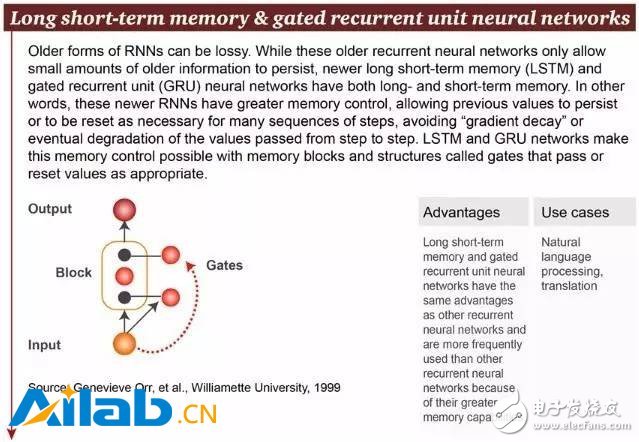
Older RNNs can be lossy because they can only hold a small amount of old information. But the new long- and short-term memory (LSTM) and gated recurrent unit (GRU) neural networks have both long-term and short-term memory. In other words, these newer RNNs have better memory control, allowing previous values ​​to be saved or, if necessary, reset for many sequence steps, avoiding "gradient decay" during the step-to-step transfer. . The LSTM and GRU networks implement this memory control by properly passing or resetting the values ​​of memory blocks and structures called gates.
9. Convolutional neural networks
The Convolutional Neural Network (CNN) is a feedforward neural network. Its artificial neurons can respond to a part of the coverage area, and have excellent performance for large image processing and drug discovery.
A convolutional neural network consists of one or more convolutional layers and a fully connected layer at the top (corresponding to a classical neural network), including associated weights and pooling layers. This structure enables the convolutional neural network to take advantage of the two-dimensional structure of the input data. Compared to other deep learning structures, convolutional neural networks can give better results in terms of image and speech recognition. This model can also be trained using backpropagation algorithms. Compared to other depth, feedforward neural networks, convolutional neural networks require fewer parameters to estimate.
Gan 150W,Usb Pd Charger,Charger Gan,Gan Adapter
ShenZhen Yinghuiyuan Electronics Co.,Ltd , https://www.yhypoweradapter.com